Road to VLA
Mar 25th 2026 ·Yahya Masri, Akshith Ambekar, Abhi Maddi
Nobody really understands VLAs end-to-end, and neither do we. We started this project to learn by building each piece ourselves from first principles.

How a VLA model works
Why did we start this project?
We picked this because it is hard. We did not want to stay at the API layer; we wanted to understand how perception, language, and action connect.
- We use LLM tools daily, but we want first-principles understanding.
- There is still no clear beginner path from model outputs to real-world robot actions.
Our design philosophy is simple: build first, read later. We prototype, fail, debug, then return to papers with sharper questions.
We also want to train a style of thinking: patient, deliberate, and grounded in fundamentals. Instead of treating VLAs like black boxes, we document each assumption and share progress publicly as we go.
Throughout this project, we learn by drawing system diagrams, writing assumptions down, and validating each step in code. The goal is an inspectable, reproducible learning path.
Before we move forward, one clarification: this is not a production VLA replica. It is our attempt to re-invent the core ideas ourselves.
What is a VLA model?
A VLA model unifies vision, language, and action in one model. Given images, text, and state, it predicts actions.
In practice, this lets robots follow instructions, manipulate objects, and generalize to new scenes with less task-specific retraining.
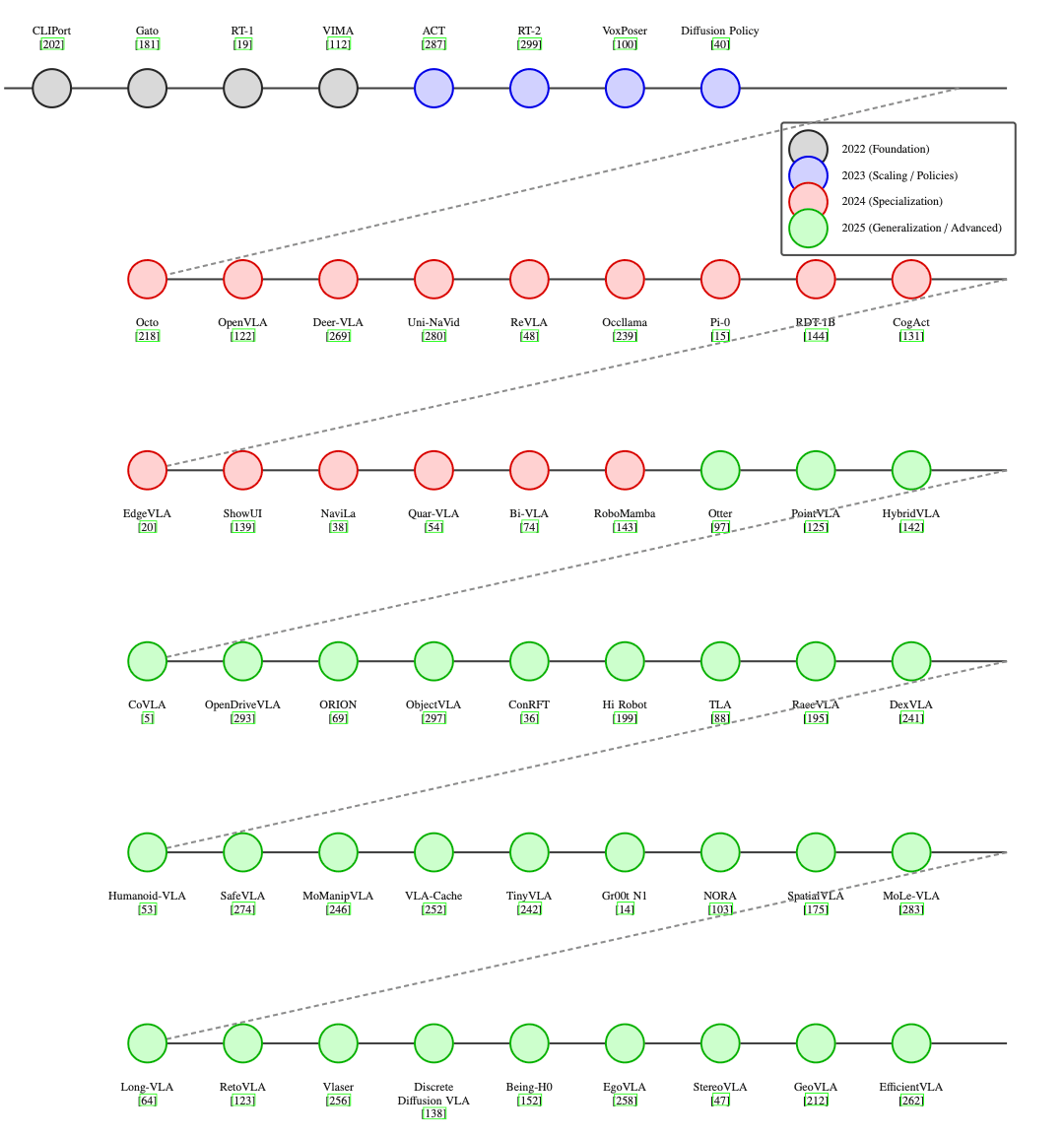
Brief timeline:
VLAs have moved from pure vision-language pretraining to policy fine-tuning and then to broader generalist systems.
The current frontier focuses on reliability: safer behavior, better grounding, and stronger real-world transfer.
How a VLA model is trained
Before we dive into architecture details, we should cover training. Modern VLA pipelines combine web-scale semantic supervision with robot interaction data.
At a high level, the training mix has two parts:
- Web-scale semantic data: image-caption pairs, instruction-following, and visual question-answering corpora that teach language-grounded perception.
- Robot interaction data: demonstration datasets; real or simulated.

Training data composition for VLA models: web-scale semantic data and robot interaction trajectories.
This is the right place to discuss full training pipelines, but first we need the core building blocks that make a VLA possible.
What is a Neural Network?
A neural network is a function approximator made of layers of neurons. Each neuron combines inputs, applies weights, and outputs an activation. The simplest version is a multilayer perceptron (MLP).

What is a neuron in this context? It is a single scalar value, usually called an activation. For digit classification[1], an MLP might have 3-4 layers: an input layer, one or two hidden layers, and an output layer of 10 neurons. In the input layer, each pixel maps to one activation (black near 0, white near 1). The output neuron with the highest activation is the predicted digit.

Figure 1 of 3
Input and output layers are intuitive, but hidden layers raise the key question: how does one layer determine the next? Through weights. A weight scales an incoming activation and controls how strongly one neuron influences another.

Take one neuron in a hidden layer with eight incoming connections. Each incoming activation is multiplied by its corresponding weight, and those products are summed. That weighted sum becomes the neuron's pre-activation signal.
So where do weights come from? Are they predefined? We start with random values. At firs the network performs poorly, then training updates the weights to reduce prediction error.
Furthermore, to keep activations bounded in this toy example, we use a sigmoid function. Large negative inputs map near 0, and large positive inputs map near 1.

What is bias? Bias is a skew in how a model interprets input and produces outputs. It does not come from the architecture itself, but from the data and training process. In pratice, bias shows up when certain patterns are overrepresented and others are missing. One example we can use to think about this is the number 7. Both the numbers 1 and 7 share a vertical line, so if a model has seen far more examples of the number 1, it may associate that vertical feature too strongly with 1 and misclassify a 7, especially if the distinguishing features are less common. This happens because the model learns to rely on patterns that appear most frequently, not necessarily the ones that are most informative.
Zooming back out a bit, in our example, recall that our input layer had 576 neurons (24 x 24). Let us focus on an arbitrary neuron, call it neuron_x, in the second layer. The activation value for neuron_x is computed by taking the weighted sum of all 576 input neurons, adding a single bias term for neuron_x, and then applying the sigmoid function to that result. Like we mentioned, all these weights and biases are initalized randomly, and the process of finding the the right weights and biases is called Learning.
After all this, we think it is pretty clear that a neuron is no longer just a thing that holds a a number called the activation, but rather a function. Furthermore, one question naturally comes up: why do we even use sigmoid here? As we briefly mentioned, sigmoid squashes values between 0 and 1, which helps keep activations bounded. However, this squashing also comes with a downside. When the input becomes very large or very small, the output of the sigmoid function changes very little. This means the neuron becomes less sensitive to changes in its input, making learning slower. An alternative that is often used in practice is the ReLU (Rectified Linear Unit) function. Instead of squashing values, ReLU simply outputs 0 for negative inputs and keeps positive inputs unchanged. This allows strong signals to pass through without being compressed, which makes it easier for the network to learn meaningful patterns. So while sigmoid helps us understand the idea of activations in a clean, bounded way, ReLU is often preferred in real systems because it preserves more information and leads to faster, more stable learning.

Gradient Descent
So far, we have defined how a neuron computes an activation from weights and biases. The next question is: how do we update those parameters so the network improves?
We do this with a cost (loss) function. The loss measures how far the network's predictions are from the correct answers. High loss means poor performance; low loss means better performance.
In practice, the exact loss depends on the task. Common choices include:
- Mean Squared Error (MSE)
- Categorical Cross-Entropy
- Binary Cross-Entropy
- Logarithmic Loss (Log Loss)
For intuition, imagine minimizing a simple 1D function. If the slope is positive, you step left. If the slope is negative, you step right. In many dimensions, that slope generalizes to the gradient: a vector that points in the direction of steepest increase.

Local minimum: the lowest point within a nearby region of the loss surface.
Global minimum: the absolute lowest point across the full loss surface.
Gradient descent repeats one update: compute the gradient, then move parameters a small step in the negative-gradient direction (scaled by a learning rate). Over many updates, weights and biases shift so predictions become less random and more aligned with targets. That iterative minimization process is what we call learning.[2]
Quick concept: a large enough NN can memorize both structured and random labels, but optimization is usually easier on structured data, so the loss curve tends to drop faster.
Stochastic Gradient Descent
So far, we described gradient descent as updating parameters using the cost over the full training set. In practice, that full computation is often too expensive because it requires evaluating very large numbers of examples at once.
Stochastic gradient descent (SGD) solves this by using a small subset of data at each step, usually called a mini-batch. Instead of computing the exact full-dataset gradient, SGD uses a local estimate from that batch and updates immediately.
These updates are noisier because each mini-batch only sees part of the data. So the optimization path is not perfectly smooth; it jitters while still trending downhill.

That noise is often helpful, not harmful. It can speed up training and help the model avoid getting stuck in certain regions of the loss landscape. Over many iterations, SGD still drives the network toward a minimum while being much more computationally efficient than full batch updates.
Backpropagation
So far, we have covered forward pass and loss. The next question is: how do we know which specific weights and biases to change, and by how much?
Backpropagation answers that question. After computing the loss, we propagate error signals backward through the network and compute gradients for each parameter. These gradients tell us how sensitive the loss is to small changes in each weight and bias.
Mathematically, this is an efficient application of the chain rule across layers. Instead of recomputing everything from scratch for each parameter, backprop reuses intermediate terms while moving from output layers back to earlier layers.
- Run a forward pass to get predictions.
- Compute loss against targets.
- Backpropagate to compute parameter gradients.
- Use an optimizer (for example, gradient descent) to update parameters.
Quick distinction: backpropagation computes gradients; the optimizer applies updates. Together, they drive learning.
New section 3
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse potenti. Morbi vulputate justo non magna fringilla, eu posuere mauris tincidunt. Sed in tempor eros, vitae bibendum nunc. Nunc aliquet ullamcorper augue, sed pretium velit tristique a.
Footnotes
[1] MNIST dataset (labeled handwritten digit images) from Kaggle: https://www.kaggle.com/datasets/hojjatk/mnist-dataset ↩ back
[2] Gradient descent is one optimizer among many; commonly used alternatives include SGD with momentum, RMSProp, and Adam. ↩ back
References
- Vision-Language-Action (VLA) Models: Concepts, Progress, Applications and Challenges — Sapkota et al., 2025 (arXiv:2505.04769).
- NVIDIA Guide: Gradient Descent and Backpropagation — practical walkthrough of gradient descent and backpropagation with data-science-focused intuition.
Important resources
- Physical Intelligence (π) — physical intelligence homepage (VLA research lab).
- TurboQuant Paper — algorithm that compresses AI models (especially LLM KV caches and vector databases) without losing accuracy, while also making them faster and cheaper to run.
- nanochat — minimal, hackable single-node LLM training harness that covers tokenization, pretraining, finetuning, evaluation, inference, and a chat UI; includes a depth dial for training compute-optimal model sizes.
- NVIDIA Cosmos-Reason1 (Project Page) — project overview from NVIDIA Research on physical common sense and embodied reasoning.
- Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning (arXiv 2503.15558v1) — technical paper detailing the model architecture, four-stage training pipeline, and physical AI reasoning benchmarks.